|
Brown University |
Brown University |
Brown University |
|
|
|
|
|
Many pretrained multilingual models exhibit cross-lingual transfer ability, which is often attributed to a learned language-neutral representation during pretraining. However, it remains unclear what factors contribute to the learning of a language-neutral representation, and whether the learned language-neutral representation suffices to facilitate cross-lingual transfer. We propose a synthetic task, Multilingual Othello (mOthello), as a testbed to delve into these two questions.
We find that:
|
|
|
|
|
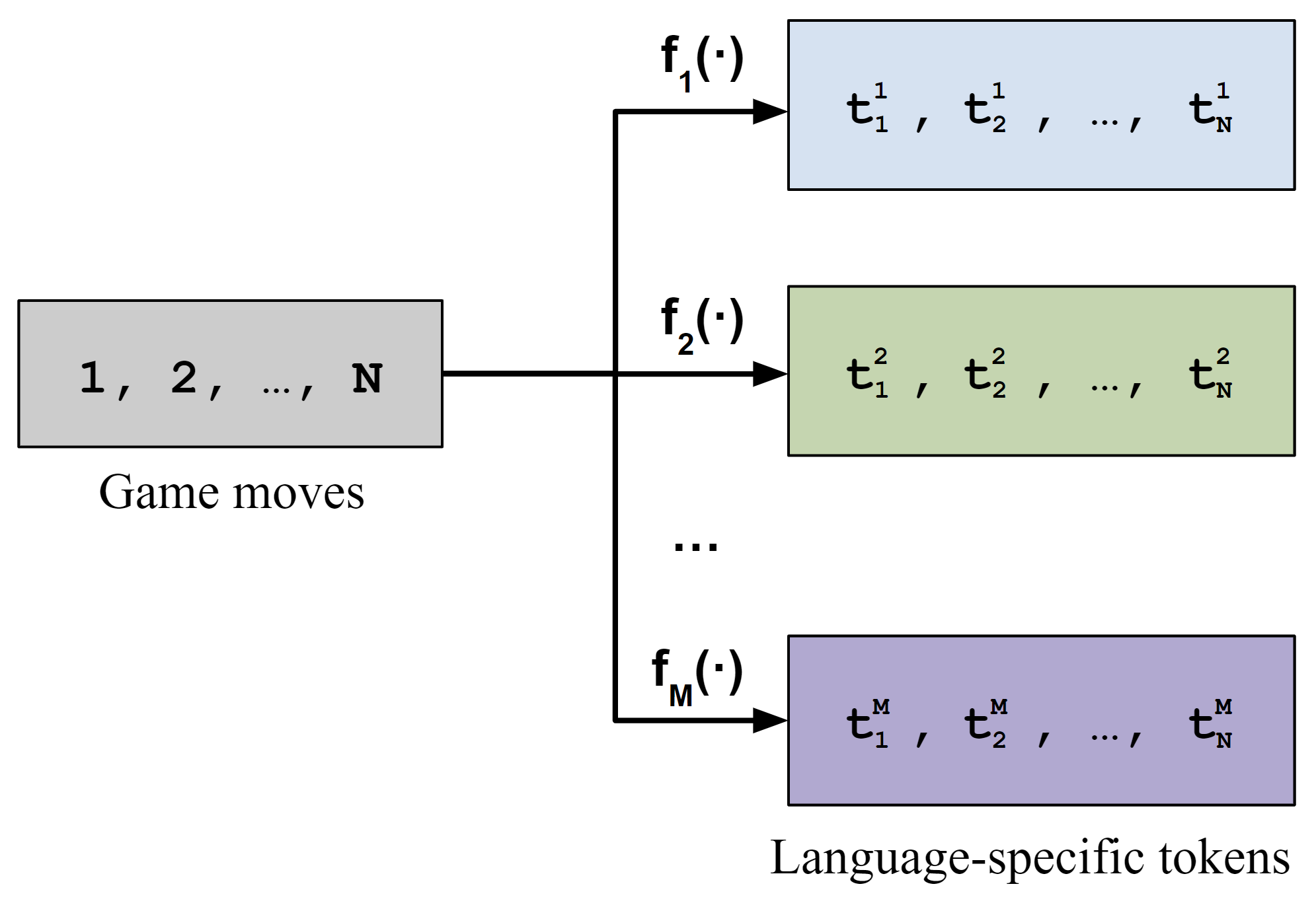
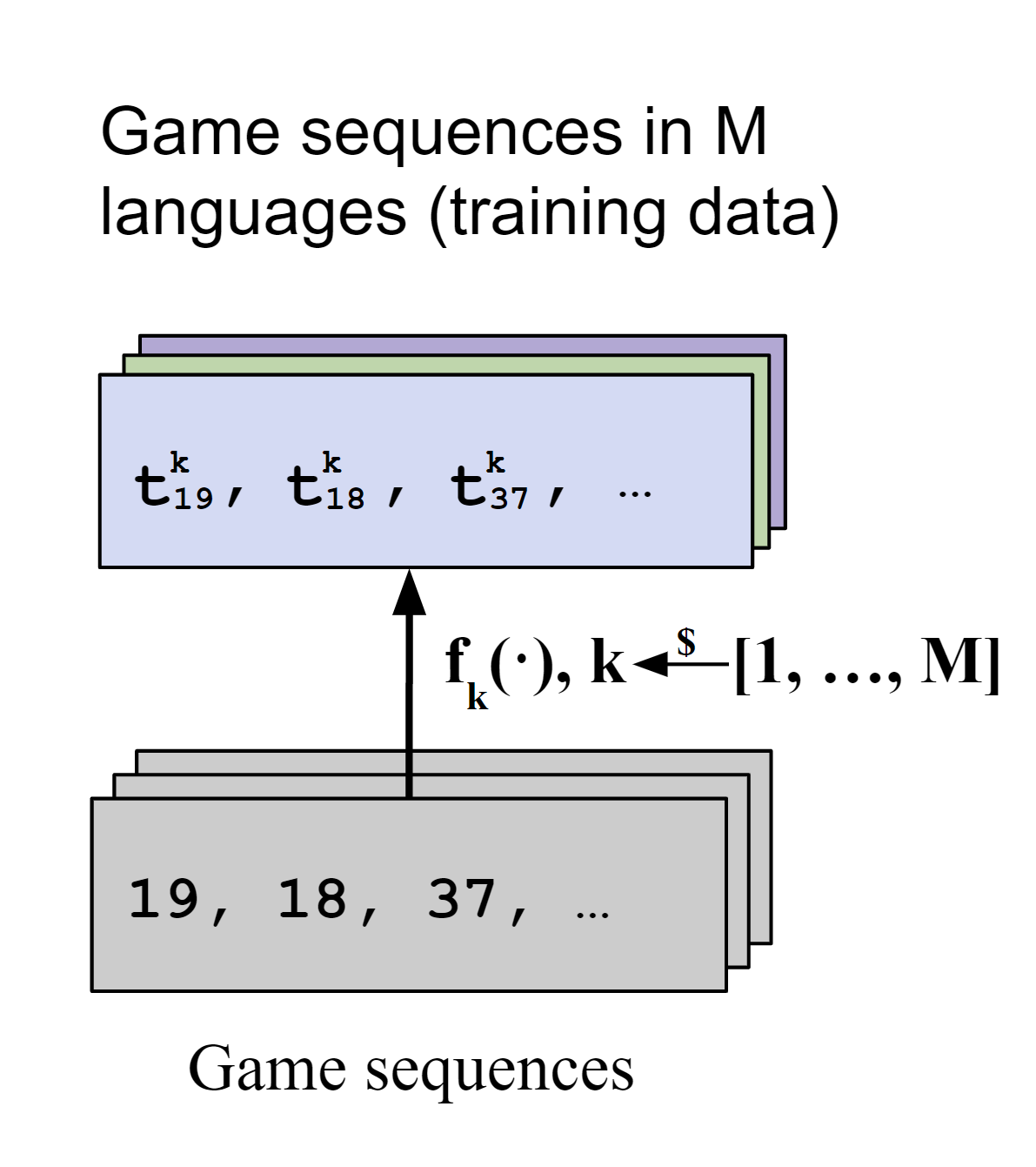
We use Multilingual Othello (mOthello), a sequence modeling task based on the Othello board game to investigate the essential factors for learning language-neutral representations and whether they are sufficient to facilitate the cross-lingual transfer ability of multilingual models. In mOthello, a model is given a sequence of game moves in a specific "language", and the task is to predict the next legal move in the same "language". This environment is appropriate for our purposes, since it separates the ground truth "world" (i.e., the game state) which is assumed to be singular, from the language used to describe it, which can take any number of forms (languages). We later formulate our measure of language-neutral representations around the ground-truth underlying world states. The figures above show how mOthello instances can be used to generate a corpus of multilingual data for training and evaluation. To test the generalizability of our findings beyond the simple mOthello languages, we introduce three variants of mOthello languages to mirror features of natural languages:
|

|
|
With training data generated via mOthello, we train GPT-2 (mOthelloGPTs) with different multilingual pretraining approaches (as illustrated in the figure above). Block "M" represents an mOthelloGPT. Blue and green blocks represent words in 2 different languages.
|
|
|
|
To measure to what extent the hidden representations of semantically similar tokens across languages align with one another, we propose cross-lingual alignment probes, which is a probe Psrc trained to recover the board states with input sequences in language Lsrc to recover the board states given input sequences in another language Ltgt, in a zero-shot fashion. If a cross-lingual alignment probe can reconstruct the board states in another language accurately, this reflects that there is a shared latent space for language Lsrc and Ltgt. |
|
Cross-lingual transfer ability is the ability to enhance task performance in a target language when being finetuned exclusively with labeled data from the same task, but in a different source language. To measure the cross-lingual transfer ability of mOthelloGPT models, we first pretrain mOthelloGPTs on a prefix-filtered subset of the mOthello corpus, translated to M languages; then, we finetune the pretrained model with a non-prefix-filtered subset of the entire mOthello corpus, but only in one of the languages. We record checkpoints during finetuning process and measure the alignment and performance for each model checkpoint. The performance is measured by calculating the top-1 accuracy of legal move prediction in each language. If a model can achieve better performance in a target language when finetuned solely on the source language, this reflects that the model has good cross-lingual transfer ability. |
|
1. Models Trained with Naive Multilingual Pretraining Fail to Learn a Language-neutral Representation, But the Introduction of Anchor Tokens Helps |
 |
|
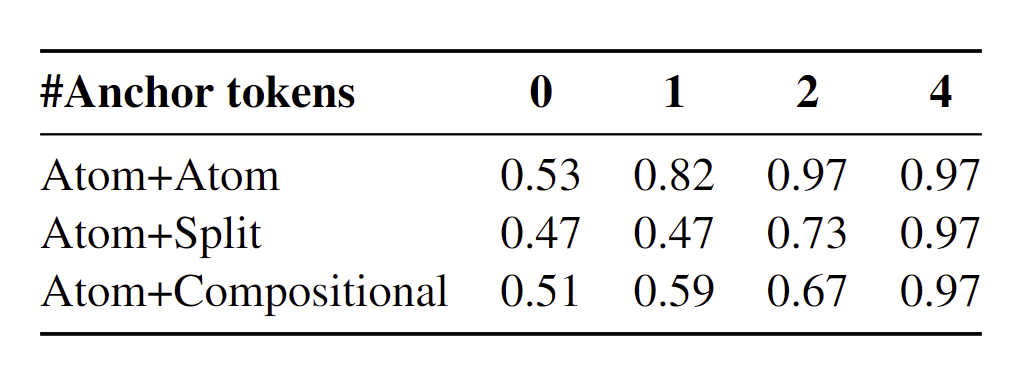
The first column of the table above shows the pairwise cross-lingual alignment probe accuracy in mOthelloGPTs trained on different language pairs using the naive training approach (with no anchor tokens). We observe a lack of strong alignment in the representations across all pairs of languages, implying that naive bilingual pretraining without any inductive biases may not yield representation alignment across languages.
Multilingual Othello allows us to introduce anchor tokens, which are the shared tokens across languages. We observe that as the number of shared anchor tokens across two languages increases, the alignment of representations improves. More specifically, with 4 shared anchor tokens, the representations already reach nearly perfect alignment for all three language-pair types. This suggests that the introduction of anchor tokens can help induce the learning of language-neutral representations. |
|
2. Learning Langauge-neutral Representations Is Not Sufficient for Cross-lingual Transfer
|
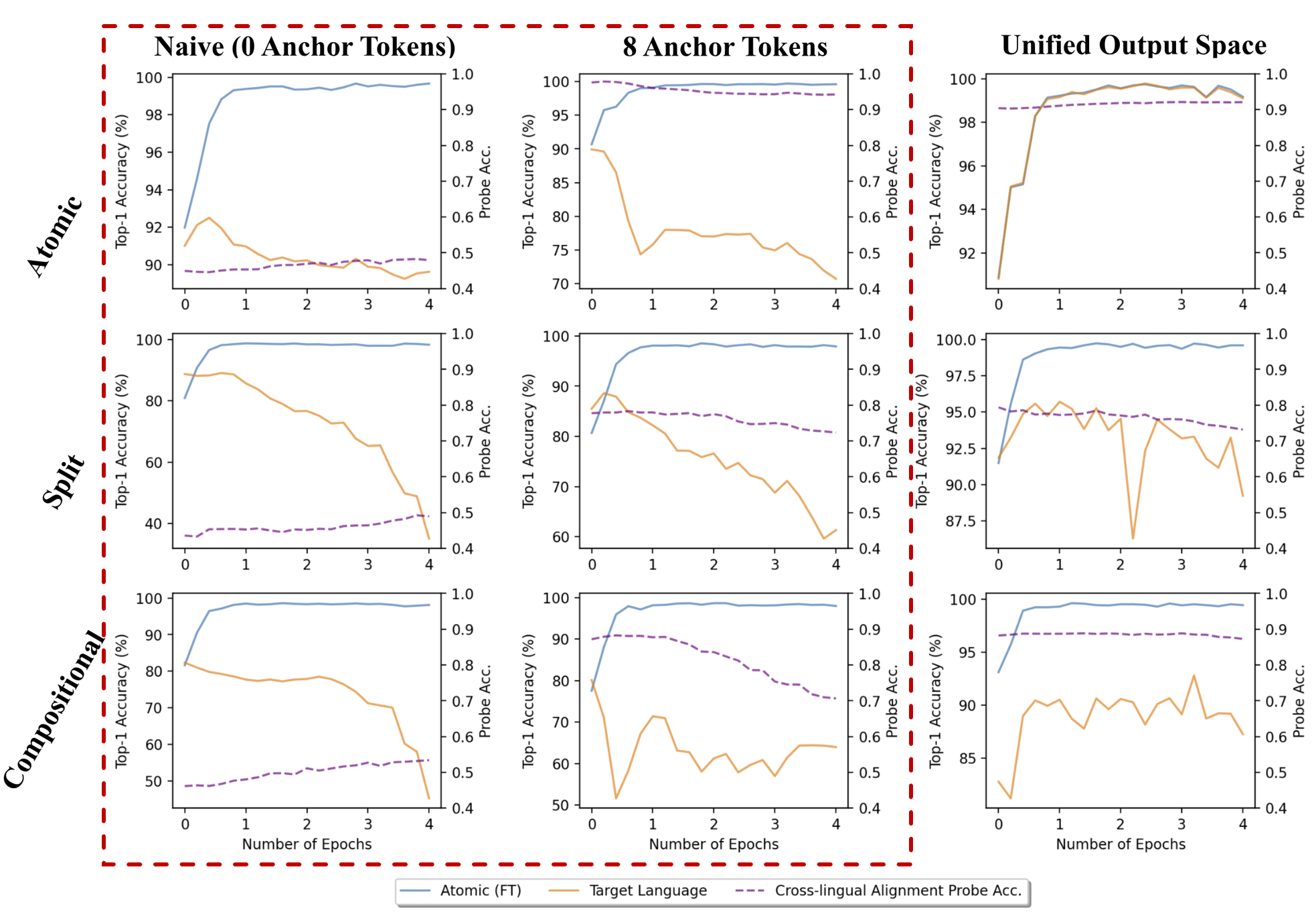 |
Next, we study whether aligned cross-lingual representations lead to cross-lingual transfer ability for mOthelloGPTs. The first and second columns in the figure above present cross-lingual transfer results of mOthelloGPTs trained with or without anchor tokens. We observe that
|
|
3. Multilingual Pretraining with Unified Output Space Brings Both Representation Alignment and Cross-lingual Transfer |
 |
|
The third column in the figure above shows the results of representation alignment and cross-lingual transfer learning under the multilingual pretraining with unified output space. We observe that pretraining with unified output space brings mOthelloGPTs not only cross-lingual alignment, but also cross-lingual transfer ability. Specifically, for mOthelloGPT pretrained with Atomic language pairs, the cross-lingual alignment probe accuracy remains at around 90%, indicating that the FT source language and the target language are well aligned. Moreover, we observe that despite not encountering any sequences from the target language during finetuning, this mOthelloGPT still manages to enhance its performance in predicting next legal moves in language the target language to the same extent as in the FT source language. This indicates that this mOthelloGPT achieves cross-lingual transfer under the unified output space approach. We notice that the cross-lingual transfer ability of mOthelloGPTs trained with Split or Compositional language pairs is slightly weaker, but the pattern that finetuning on the FT source language benefits next move prediction in the target language still holds, especially at early finetuning phase.
The improvement in performance of target language across three language pairs of structurally different languages implies that multilingual pretraining with unified output space is an effective approach for inducing cross-lingual alignment and cross-lingual transfer ability and is robust to structural differences across languages. |
| 4. Multilingual Training with More Than Two Languages |
 |
Here, we explore whether our findings hold for multilingual models that are trained with more than two languages. The above figure shows the cross-lingual representation alignment and cross-lingual transfer performance of mOthelloGPTs trained with 4 languages consisting of different language types.
We find that the results are consistent with our findings on bilingual mOthelloGPTs:
|
 |
Tianze Hua*, Tian Yun*, Ellie Pavlick. mOthello: When Do Cross-Lingual Representation Alignment and Cross-Lingual Transfer Emerge in Multilingual Models? In NAACL 2024 (Findings). |
|
AcknowledgementsThis template was originally made by Phillip Isola and Richard Zhang for a colorful ECCV project; the code can be found here. |